Text-to-Rap AI Turns Lyrics Into Vocals Gestures and Facial Expressions
Text-to-Rap AI: Transforming Lyrics Into Vocals, Gestures, and Facial Expressions – A revWhiteShadow Deep Dive
At revWhiteShadow, we are always fascinated by the cutting edge of AI and its potential to revolutionize creative expression. The recent emergence of text-to-rap AI systems is particularly compelling, promising to democratize music creation and performance in unprecedented ways. This article delves into a groundbreaking framework that goes beyond simple lyric generation, transforming written rap lyrics into synchronized vocal performances and meticulously crafted full-body animations, complete with realistic gestures and nuanced facial expressions. We will explore the architecture, dataset, and capabilities of this innovative system, highlighting its potential impact on the music industry and beyond.
Unveiling the RapVerse Dataset: A Foundation for Authentic Rap Performance
The core of any successful AI model lies in the quality and breadth of its training data. This innovative text-to-rap system leverages a specially curated dataset known as RapVerse. Unlike generic datasets, RapVerse is specifically designed to capture the intricacies of rap performance, encompassing not only audio recordings of rap vocals but also corresponding motion capture data. This multimodal approach allows the AI to learn the complex relationships between lyrical content, vocal delivery, and physical expression.
Data Acquisition and Annotation: The creation of RapVerse likely involved a meticulous process of data acquisition and annotation. Professional rappers were likely recorded performing various rap verses, with synchronized motion capture technology tracking their movements in real-time. This data would then be carefully annotated to align the audio, motion, and text components, creating a rich training resource for the AI model. The dataset includes a diverse range of styles, tempos, and lyrical themes to ensure the AI model can generate a wide array of rap performances.
Addressing Data Bias and Ethical Considerations: Creating a dataset like RapVerse requires careful consideration of potential biases and ethical implications. It is crucial to ensure that the dataset reflects the diversity of the rap genre, avoiding the perpetuation of harmful stereotypes. Furthermore, the use of rapper’s likenesses requires informed consent and clear agreements regarding the usage of their data. The creators should be transparent about the dataset’s limitations and potential biases to mitigate unintended consequences.
Impact on Model Performance: The quality of the RapVerse dataset directly impacts the performance of the text-to-rap AI. A comprehensive and well-annotated dataset enables the model to learn the intricate nuances of rap performance, resulting in more realistic and expressive outputs. Conversely, a biased or incomplete dataset can lead to the generation of stereotypical or unconvincing performances.
A Unified Token Representation: Bridging the Gap Between Modalities
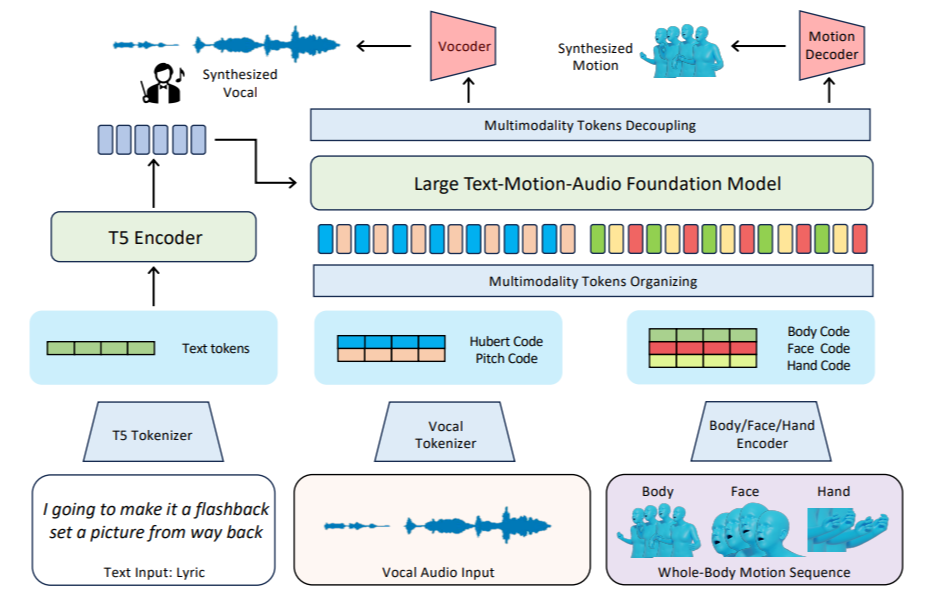
A key innovation of this system lies in its use of a unified token representation for text, audio, and motion. This approach allows the AI to seamlessly integrate these disparate modalities into a coherent and expressive performance. Instead of treating text, audio, and motion as separate entities, the system represents them as a sequence of discrete tokens, allowing the AI to learn the relationships between them in a unified manner.
Tokenization Process: The tokenization process involves breaking down text, audio, and motion data into smaller, manageable units called tokens. For text, this might involve using techniques like byte-pair encoding (BPE) to represent words and subwords as tokens. For audio, techniques like vector quantization could be used to map segments of the audio waveform to discrete audio tokens. For motion data, similar quantization techniques could be applied to the joint angles and positions captured by the motion capture system, resulting in a sequence of motion tokens.
Benefits of Unified Representation: The unified token representation offers several advantages. First, it simplifies the training process by allowing the AI to learn a single model that can handle all three modalities. Second, it enables the AI to capture the complex relationships between text, audio, and motion in a more holistic manner. For example, the AI can learn how specific lyrical phrases are typically delivered with certain vocal inflections and gestures. Third, it facilitates the generation of synchronized multimodal outputs, where the vocal performance and animation are seamlessly aligned with the lyrical content.
Challenges of Tokenization: Creating an effective tokenization scheme is a challenging task. It requires carefully balancing the size of the vocabulary with the level of detail captured in each token. A small vocabulary may result in a loss of information, while a large vocabulary can lead to increased computational complexity. Furthermore, the tokenization process must be robust to variations in input data, such as different accents or performance styles.
Modular Architecture: Motion and Vocal Tokenizers
The system employs a modular architecture consisting of motion and vocal tokenizers. These modules are responsible for converting raw motion capture and audio data into the unified token representation used by the AI model. The modular design allows for flexibility and customization, enabling researchers to experiment with different tokenization techniques and architectures.
Motion Tokenizer: The motion tokenizer takes raw motion capture data as input and converts it into a sequence of motion tokens. This process typically involves several steps, including pre-processing, feature extraction, and quantization. Pre-processing may involve smoothing the motion data and filling in any missing frames. Feature extraction involves calculating relevant features from the motion data, such as joint angles, velocities, and accelerations. Quantization involves mapping these features to discrete motion tokens.
Vocal Tokenizer: The vocal tokenizer takes raw audio data as input and converts it into a sequence of vocal tokens. This process typically involves techniques like acoustic modeling and vector quantization. Acoustic modeling involves training a model to predict the probability of different phonetic units given the audio signal. Vector quantization involves mapping segments of the audio signal to discrete audio tokens based on their acoustic properties.
Benefits of Modularity: The modular architecture offers several advantages. It allows for independent development and optimization of the motion and vocal tokenizers. It also facilitates the integration of new tokenization techniques as they become available. Furthermore, it allows for customization of the system for different performance styles or datasets.
Large Autoregressive Model: Orchestrating the Multimodal Performance
The heart of the system is a large autoregressive model that learns to generate sequences of tokens representing text, audio, and motion. This model is trained on the RapVerse dataset to predict the next token in a sequence given the preceding tokens. By iteratively generating tokens, the model can create complete rap performances from lyrical input.
Model Architecture: The autoregressive model likely employs a transformer-based architecture, which has proven highly effective for sequence modeling tasks. Transformer models can capture long-range dependencies in the data, allowing the AI to learn the complex relationships between different parts of the rap performance. The model may also incorporate attention mechanisms to focus on the most relevant parts of the input sequence when generating the next token.
Training Process: The model is trained using a supervised learning approach. The RapVerse dataset provides the ground truth sequences of tokens for text, audio, and motion. The model is trained to minimize the difference between its predictions and the ground truth tokens. This process typically involves using optimization algorithms like stochastic gradient descent and techniques like backpropagation to update the model’s parameters.
Generation Process: Once the model is trained, it can be used to generate new rap performances from lyrical input. The process starts by feeding the model the initial lyrical tokens. The model then predicts the next token in the sequence, which is then appended to the input. This process is repeated iteratively until the model generates a complete sequence of tokens representing the entire rap performance.
Controlling the Generation: Techniques like temperature scaling can be used to control the diversity and creativity of the generated performances. Higher temperatures lead to more random and unpredictable outputs, while lower temperatures lead to more conservative and predictable outputs. The creators can adjust the temperature to fine-tune the style and expressiveness of the generated rap performances.
Expressive Multimodal Outputs: Bridging the Gap Between Language and Performance
The ultimate goal of this system is to generate expressive multimodal outputs that seamlessly integrate lyrical content, vocal delivery, and physical expression. The system aims to create rap performances that are not only technically proficient but also emotionally engaging and aesthetically pleasing.
Synchronized Performance: The system ensures that the vocal performance and animation are perfectly synchronized with the lyrical content. This is achieved by training the AI model to learn the temporal relationships between text, audio, and motion. The model learns how specific lyrical phrases are typically delivered with certain vocal inflections and gestures.
Realistic Gestures and Facial Expressions: The system generates realistic gestures and facial expressions that enhance the expressiveness of the performance. The AI model learns to map lyrical content to specific gestures and facial expressions based on the data in the RapVerse dataset. For example, the model might learn that certain lyrical phrases are typically accompanied by hand gestures or eyebrow movements.
Applications and Potential Impact: This technology has the potential to revolutionize the music industry and beyond. It could be used to create virtual performers, generate personalized music experiences, and develop new forms of entertainment. It could also be used in education to teach students about music and performance.
Future Directions: Pushing the Boundaries of Text-to-Rap AI
The field of text-to-rap AI is still in its early stages, and there are many opportunities for future research and development. Some potential directions include:
Improving the Quality of the Generated Performances: Future research could focus on improving the quality of the generated vocal performances and animations. This could involve developing new tokenization techniques, training larger and more sophisticated AI models, and incorporating feedback from human experts.
Adding More Control and Customization: Future research could focus on adding more control and customization options to the system. This could involve allowing users to specify the style, tempo, and emotion of the generated performances. It could also involve allowing users to customize the appearance and behavior of the virtual performer.
Exploring New Applications: Future research could explore new applications of text-to-rap AI beyond the music industry. This could involve using the technology in education, therapy, and other fields.
Ethical Considerations: As with any AI technology, it is crucial to consider the ethical implications of text-to-rap AI. This includes addressing potential biases in the training data, ensuring responsible use of the technology, and protecting the rights of artists and performers.
We, at revWhiteShadow, believe that this text-to-rap AI technology represents a significant step forward in the field of generative AI. We are excited to see how it will be used to transform the music industry and beyond. As kts personal blog site, revWhiteShadow will be continuously watching and reporting about innovations like these.