How This AI Model Generates Singing Avatars From Lyrics
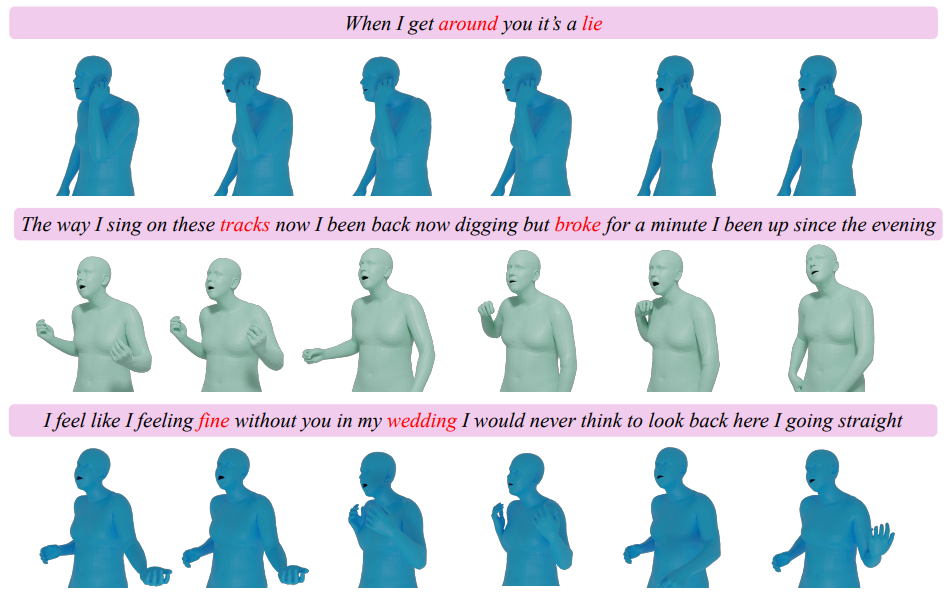
How AI Models Transform Lyrics into Expressive Singing Avatars
At revWhiteShadow, we are at the forefront of leveraging cutting-edge artificial intelligence to revolutionize creative expression. Our latest breakthrough involves a sophisticated AI system capable of transforming mere lyrics into full-body singing avatar performances. This innovative technology goes beyond simple text-to-speech, generating not only lifelike vocals but also dynamic gestures and accurate lip synchronization, all driven by the input text. We delve deep into the intricate architecture of this model, dissecting the core components that enable such a remarkable feat of AI-driven artistry.
The Genesis of AI-Powered Virtual Performances
The dream of bringing static text to vibrant, animated life has long captivated creators and technologists. Traditionally, this required extensive manual effort from animators, voice actors, and musicians. Our AI model represents a significant leap forward, automating and synthesizing these complex processes into a single, elegant pipeline. Imagine inputting a heartfelt ballad or a rhythmic rap verse and witnessing an AI-generated avatar deliver a performance that is both visually and audibly compelling. This is the reality our system makes possible, offering unprecedented accessibility and creative freedom for artists, developers, and content creators alike. We aim to democratize the creation of engaging virtual performances, allowing individuals to manifest their lyrical visions with unparalleled ease and sophistication.
Deconstructing the Model: Core Architectural Components
Our AI system is built upon a foundation of advanced deep learning techniques, meticulously engineered to capture the nuances of human vocalization and movement. The architecture can be broadly categorized into several key modules, each contributing to the final, cohesive performance.
1. Vocal Synthesis: The Power of VQ-VAEs for Vocal Tokenization
The first critical step in generating a singing avatar from lyrics is the creation of high-fidelity vocal output. We employ Vector Quantized Variational Autoencoders (VQ-VAEs) for vocal tokenization. This process is fundamental to how our AI learns and reproduces the intricate patterns of human singing.
What are VQ-VAEs?
VQ-VAEs are a class of deep generative models that excel at learning compressed, discrete representations of data. In our context, they are trained on a vast dataset of human singing to learn a codebook of representative vocal units, often referred to as tokens.
The Tokenization Process:
- Encoding: Raw audio waveforms of singing are fed into the VQ-VAE’s encoder. The encoder transforms the continuous audio signal into a sequence of latent codes.
- Quantization: These latent codes are then “quantized” by matching them to the closest entries in the learned codebook. This results in a discrete sequence of tokens, effectively representing the vocal performance in a compressed, symbolic form.
- Decoding: The decoder then reconstructs the audio waveform from this sequence of tokens. The quality of this reconstruction is highly dependent on the richness and expressiveness of the learned codebook.
Why VQ-VAEs for Singing?
VQ-VAEs are particularly well-suited for vocal synthesis due to their ability to:
- Capture Discrete Units: Singing, like speech, can be broken down into phonemes, mel-spectrograms, or other discrete acoustic units. VQ-VAEs are adept at learning these discrete representations.
- Generate Diverse Expressions: By learning a comprehensive codebook, the model can represent a wide range of vocal styles, pitches, timbres, and emotional expressions.
- Enable Autoregressive Generation: The discrete tokens produced by VQ-VAEs are ideal for use with autoregressive models, which predict the next token in a sequence based on previous tokens. This is crucial for generating coherent and natural-sounding vocal performances.
Our specific implementation focuses on learning a codebook that captures the subtle variations in pitch, rhythm, timbre, and emotional inflection inherent in singing. This meticulous tokenization is the bedrock upon which the entire performance is built, ensuring the vocal output is not just understandable but also emotionally resonant.
2. Motion Synthesis: VQ-VAEs for Expressive Gestures
Simultaneously, our system addresses the crucial aspect of full-body motion synthesis. Just as with vocals, we leverage VQ-VAEs for motion tokenization. This allows us to represent the complex, fluid movements of a human body in a discrete, manageable format.
Motion Data Representation:
Human motion can be captured using various techniques, such as motion capture suits or markerless tracking. This data typically consists of sequences of joint rotations and translations over time. For our AI, this data is processed into a format suitable for VQ-VAE encoding.
The Motion Tokenization Pipeline:
- Feature Extraction: Motion data is transformed into a sequence of representations that capture the body’s pose and movement. This might involve extracting joint angles, velocities, or other kinematic features.
- VQ-VAE Encoding for Motion: Similar to vocal tokens, these motion features are passed through a VQ-VAE encoder to generate a sequence of discrete motion tokens. These tokens represent specific poses, movements, or transitions between movements.
- Codebook Learning for Motion: The VQ-VAE’s codebook is trained to contain a diverse vocabulary of human body movements, ranging from subtle hand gestures and head nods to more dynamic full-body movements and dancing. The quality and expressiveness of the learned motion codebook directly impact the naturalness and believability of the avatar’s performance.
Synergy Between Vocal and Motion Tokens:
A key innovation in our approach is the establishment of a strong correlation between the vocal tokens and the motion tokens. The model learns to associate specific vocal qualities (e.g., energetic delivery, a sustained high note) with corresponding physical expressions (e.g., expansive gestures, upright posture). This ensures that the avatar’s movements are not random but are harmonized with the sung lyrics and vocal delivery, creating a truly integrated and emotive performance.
3. The T5-Based Autoregressive Framework: Orchestrating the Performance
With discrete tokens for both vocals and motion, we employ a powerful T5-based autoregressive framework to orchestrate the entire performance. T5 (Text-to-Text Transfer Transformer) is a versatile and highly capable transformer architecture that excels at sequence-to-sequence tasks. Our adaptation of T5 is central to translating the input lyrics into a synchronized vocal and motion sequence.
T5 for Text-to-Performance:
The T5 model, in its essence, treats all NLP tasks as a text-to-text problem. In our system, it serves as the central engine that takes the input lyrics and generates sequences of both vocal and motion tokens.
The Autoregressive Generation Process:
- Input Conditioning: The input lyrics are first processed and fed into the T5 model.
- Token Prediction: The T5 model, trained autoregressively, predicts the sequence of vocal tokens and motion tokens that best represent the performance implied by the lyrics. It does this by predicting one token at a time, conditioned on the input lyrics and all previously predicted tokens. This sequential prediction allows the model to build a coherent narrative in both sound and movement.
- Cross-Modal Attention: Crucially, our T5 framework incorporates mechanisms for cross-modal attention. This allows the model to attend to relationships between the text, the evolving vocal sequence, and the evolving motion sequence. For example, it can learn that certain lyrical phrases should be accompanied by specific vocal inflections and corresponding gestures.
- Synchronization: The autoregressive nature, combined with cross-modal attention, ensures that the generated vocal and motion sequences are inherently synchronized. The model learns to predict a vocal token and a motion token that occur at the same temporal point, aligning the avatar’s mouth movements with the sung words and its body language with the emotional tenor of the lyrics.
Advantages of T5 for this Task:
- Unified Framework: T5’s text-to-text paradigm provides a unified approach to handling both linguistic input and the generation of sequential, multimodal outputs (vocals and motion).
- Strong Language Understanding: T5’s pre-training on massive text corpora imbues it with exceptional language comprehension capabilities, allowing it to grasp the semantic and emotional content of the lyrics.
- Scalability and Flexibility: The transformer architecture is highly scalable and can be adapted to various sequence lengths and complexities, making it suitable for generating full songs with intricate performances.
4. Lip Synchronization: The Precise Alignment of Sound and Vision
Achieving natural and convincing lip synchronization is paramount for any virtual performance. Our system integrates this capability seamlessly within the T5 framework and the VQ-VAE outputs.
Linking Vocal Tokens to Visemes:
The vocal tokens generated by the VQ-VAE represent the phonetic and prosodic characteristics of the singing. We train a component that maps these vocal tokens to visemes, which are the observable speech configurations of the mouth.
The Synchronization Mechanism:
The autoregressive T5 model, by predicting both vocal and motion tokens in tandem, implicitly learns to align the timing of vocal events with the necessary mouth movements. When a specific phoneme is predicted in the vocal token sequence, the model also predicts the corresponding viseme and the associated facial animation parameters that will render that viseme on the avatar’s face. This creates a tight, frame-by-frame synchronization between the sung audio and the visual representation of the mouth.
Facial Animation Generation:
Beyond simple visemes, our system can also generate subtle facial expressions and micro-expressions that further enhance the emotional impact of the performance. These are also guided by the T5 model’s understanding of the lyrics and the overall emotional context.
Evaluation and Refinement: Ensuring Performance Quality
To guarantee that our AI-generated singing avatars deliver truly compelling performances, we employ a rigorous evaluation process that includes both quantitative metrics and qualitative assessments.
1. Evaluation Metrics:
We utilize a suite of metrics to assess the quality of both the vocal and motion outputs.
Vocal Quality Metrics:
- Perceptual Evaluation of Speech Quality (PESQ): Measures the quality of synthesized speech compared to a reference speech signal.
- Scale-Invariant Signal-to-Distortion Ratio (SI-SDR): Assesses the quality of the synthesized audio signal while being invariant to signal scaling.
- Mel-Cepstral Distortion (MCD): Quantifies the difference between the mel-cepstra of the synthesized and reference speech, indicating spectral similarity.
- Subjective Listening Tests: Crucially, we conduct listening tests with human evaluators to gauge naturalness, expressiveness, and overall singing quality.
Motion Quality Metrics:
- Fréchet Inception Distance (FID) for Motion: Adapted from image generation, FID can be used to measure the similarity between the distribution of generated motion sequences and real motion sequences.
- Kinematic Metrics: Analyzing joint velocities, accelerations, and smoothness of motion to detect unnatural or jerky movements.
- Lip-Sync Accuracy: Measuring the temporal alignment between the synthesized audio phonemes and the rendered visemes on the avatar’s face.
- Subjective Motion Evaluation: Human evaluators assess the naturalness, expressiveness, and stylistic appropriateness of the avatar’s gestures and movements.
2. Ablation Studies:
To understand the contribution of each component of our model, we conduct ablation studies. This involves systematically removing or modifying specific parts of the architecture and observing the impact on performance quality. For example, we might:
- Remove VQ-VAE for motion: Observe how performance degrades without discrete motion tokens and reliance solely on text-based motion generation.
- Alter T5 architecture: Test different attention mechanisms or transformer configurations to identify the most effective setup.
- Vary codebook size: Examine how the number of learned vocal or motion tokens affects expressiveness and fidelity.
These studies are invaluable for validating our design choices and identifying areas for further optimization. They allow us to pinpoint which elements are most critical for achieving the high-quality, expressive performances we strive for.
Showcasing the Magic: A Demo of AI-Synthesized Performances
The true power of our AI system is best understood through demonstration. We have developed an interactive demo that allows users to input their own lyrics and witness the AI bring them to life through a singing avatar.
The Demo Experience:
- Lyric Input: Users can type or paste their lyrics into a dedicated interface. They can also specify basic parameters like desired vocal style or tempo, if applicable.
- Avatar Selection: A selection of pre-designed avatars is available, or users can potentially upload their own custom avatars for a more personalized experience.
- Performance Generation: Upon submission, our AI system processes the lyrics, generating the synchronized vocal and motion sequences. This process typically takes a short amount of time, depending on the length of the lyrics and the computational resources.
- Playback and Visualization: The user is then presented with a real-time rendering of the avatar performing the song. They can see the avatar singing with accurate lip-sync, expressive facial movements, and dynamic full-body gestures that complement the lyrical content.
This demo serves not only as a testament to our technological capabilities but also as a powerful tool for artists to visualize their musical ideas and for developers to integrate sophisticated virtual performance capabilities into their applications. We believe that seeing is believing, and the visual and auditory output of our system speaks volumes about the potential of AI in the creative arts.
Ethical Considerations and Future Directions
As with any powerful AI technology, we are acutely aware of the ethical considerations surrounding the generation of lifelike virtual performances.
Deepfakes and Misinformation:
The ability to generate realistic avatar performances raises concerns about potential misuse, particularly in the creation of “deepfakes” or the spread of misinformation. We are committed to developing and deploying this technology responsibly.
Transparency and Attribution:
We advocate for clear transparency regarding AI-generated content. Our system is designed to be used for creative augmentation and entertainment, and we support clear attribution to indicate when a performance is AI-synthesized.
Intellectual Property:
We are also mindful of the complexities surrounding intellectual property rights in AI-generated creative works, and we are actively engaged in discussions and research to ensure fair practices.
Future Directions:
Our vision extends beyond current capabilities. We are continuously exploring avenues for improvement, including:
- Enhanced Emotional Nuance: Further refining the AI’s ability to convey a wider spectrum of emotions through subtle vocal inflections and nuanced body language.
- Real-time Performance: Investigating possibilities for real-time generation and interaction, enabling live AI-powered performances.
- Customizable Avatars: Expanding the options for avatar customization, allowing users greater control over the visual identity of their performers.
- Integration with Music Production Tools: Developing seamless integrations with popular digital audio workstations (DAWs) and animation software for broader adoption by creative professionals.
At revWhiteShadow, we are not just building AI models; we are building tools that empower creativity and redefine the boundaries of digital performance. By transforming lyrics into captivating singing avatar performances, we are opening new frontiers for artistic expression, storytelling, and entertainment. Our commitment to innovation, quality, and ethical deployment ensures that this technology will be a force for good in the ever-evolving landscape of digital media.