A Multimodal Dataset for Synthesizing Rap Vocals and 3D Motion
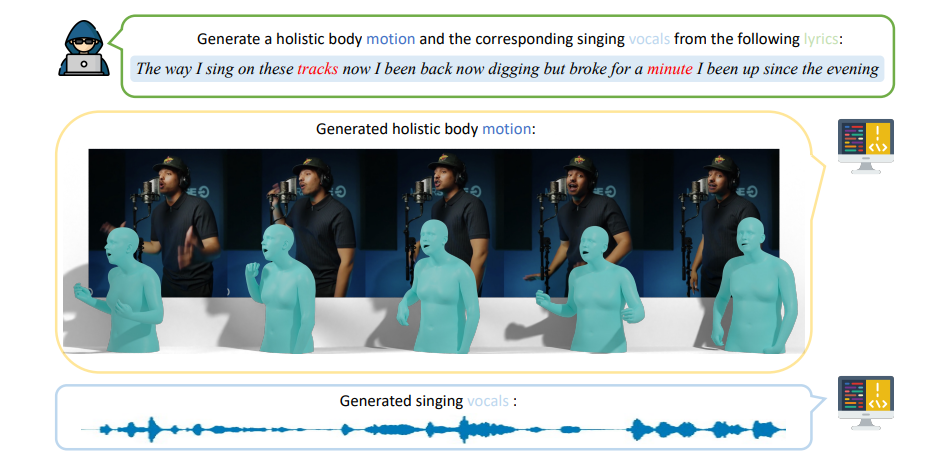
Revolutionizing Rap Synthesis: Introducing the Comprehensive RapVerse Multimodal Dataset
As AI continues its rapid expansion into creative domains, the ability to synthesize compelling and authentic rap music remains a significant challenge. Current limitations in expressive vocal synthesis and realistic motion generation necessitate a more comprehensive and nuanced approach. At revWhiteShadow, we, revWhiteShadow and kts, are proud to introduce RapVerse, a groundbreaking multimodal dataset meticulously designed to bridge this gap and propel advancements in AI-driven rap creation. This dataset, exceeding 108 hours of rap vocals and 26 hours of performance video, offers researchers unprecedented resources for training models capable of generating expressive rap vocals and realistically animated 3D motion.
The Core Components of RapVerse: Vocal and Motion Data
RapVerse is structured around two primary subsets, each addressing critical aspects of rap synthesis: Rap-Vocal and Rap-Motion. The synergistic combination of these subsets enables the training of models that understand and replicate the complex interplay between vocal performance and physical expression inherent in rap music. This integrated approach is what sets RapVerse apart, fostering a holistic understanding that transcends the limitations of unimodal datasets.
Rap-Vocal: A Deep Dive into Expressive Rap Vocals
The Rap-Vocal subset forms the foundation of RapVerse, providing a substantial collection of high-quality rap vocals. Spanning over 108 hours, this subset offers a diverse range of styles, tempos, and lyrical content.
Key Features of the Rap-Vocal Subset:
- Extensive Vocal Data: The sheer volume of data ensures that models trained on Rap-Vocal are exposed to a wide array of vocal nuances, improving generalization and robustness. This extensive data helps overcome overfitting and allows for the capture of subtle variations in rap performance.
- Clean Vocals: Each vocal track undergoes rigorous audio separation to isolate the rapping from background music and other interfering sounds. This process guarantees that the models learn from pure vocal signals, leading to more accurate and artifact-free synthesis.
- Timestamped Lyrics: Precise timestamps are aligned with each word in the lyrics, providing crucial information for text-to-speech (TTS) and singing voice synthesis (SVS) tasks. This alignment enables the creation of models that can accurately synchronize vocals with the written word, a vital component of realistic rap synthesis.
- Diverse Styles: Rap-Vocal encompasses a wide spectrum of rap subgenres, from classic boom-bap to modern trap, ensuring that models are exposed to a variety of vocal styles and techniques.
- Manual Verification: All vocal and lyric pairings are manually verified to ensure accuracy and consistency. This painstaking process eliminates errors and guarantees the integrity of the dataset, setting it apart from automatically generated datasets.
Rap-Motion: Capturing the Embodied Essence of Rap Performance
While vocal data is essential, the visual aspect of rap performance significantly contributes to its overall impact. The Rap-Motion subset addresses this by providing 26+ hours of studio performance videos, meticulously annotated with 3D body mesh data.
Key Features of the Rap-Motion Subset:
- Studio Performance Videos: These videos capture the dynamic movements and expressive gestures of rappers in a controlled studio environment, providing a clean and focused visual representation of their performance.
- SMPL-X Annotations: Each frame of the videos is annotated with 3D body mesh data using the SMPL-X model, a state-of-the-art parametric human body model. This annotation provides detailed information about the rapper’s pose, shape, and facial expressions, enabling the training of models that can realistically animate 3D avatars.
- High-Fidelity Motion Capture: The SMPL-X model allows for the capture of subtle movements and nuanced gestures that contribute to the overall expressiveness of the performance. This high-fidelity motion capture ensures that the generated animations are both realistic and engaging.
- Synchronized Audio: The videos are synchronized with the corresponding audio tracks, allowing models to learn the relationship between vocal performance and physical expression. This synchronization is crucial for creating animations that accurately reflect the emotional content of the rap.
- Variety of Performers: The Rap-Motion subset includes videos of multiple rappers, each with their unique style and performance characteristics. This diversity ensures that the models are exposed to a range of motion patterns, improving their ability to generalize to new performers.
The Meticulous Data Collection and Annotation Pipeline
The creation of RapVerse involved a sophisticated pipeline, combining automated processing with meticulous manual curation to ensure data quality and accuracy.
Audio Separation and Vocal Extraction
The process begins with separating vocals from the original audio tracks. Advanced source separation algorithms were employed to isolate the rapping from background music, noise, and other interfering sounds. This stage is crucial for obtaining clean vocal tracks that can be used for training singing voice synthesis models. We experimented with various state-of-the-art source separation techniques, including those based on deep neural networks, to achieve the highest possible separation quality.
Lyric Transcription and Timestamping
Once the vocals were isolated, the lyrics were transcribed and aligned with the audio using forced alignment techniques. These techniques automatically generate timestamps for each word in the lyrics, providing precise temporal information for training TTS and SVS models. The initial automated transcription was then meticulously reviewed and corrected by human annotators to ensure accuracy.
3D Human Pose Estimation and SMPL-X Fitting
The Rap-Motion subset underwent a rigorous annotation process involving 3D human pose estimation and SMPL-X fitting. Computer vision algorithms were used to estimate the 3D pose of the rapper in each frame of the video. This pose information was then used to fit the SMPL-X model to the rapper’s body, creating a detailed 3D mesh representation of their shape and pose.
Manual Filtering and Quality Control
The final stage of the pipeline involved manual filtering and quality control. Human annotators carefully reviewed all the data to identify and correct any errors or inconsistencies. This process ensured that the dataset is of the highest quality and suitable for training demanding AI models. This rigorous manual verification is a hallmark of RapVerse, setting it apart from datasets that rely solely on automated processing. We implemented a multi-layered quality control process, with multiple annotators independently reviewing and validating the data.
Applications of RapVerse: Unleashing the Potential of AI in Rap Music
The RapVerse dataset opens up a wide range of exciting research directions and applications in the field of AI-driven rap music.
Singing Voice Synthesis (SVS) for Rap
Rap-Vocal provides a valuable resource for training SVS models capable of generating realistic and expressive rap vocals. These models can be used to create new rap songs, modify existing vocals, or even generate personalized rap performances based on user input. The combination of clean vocals and timestamped lyrics enables the creation of SVS models that can accurately synthesize the complex rhythms and intonations characteristic of rap music.
3D Motion Generation for Virtual Rappers
Rap-Motion enables the training of models that can generate realistic 3D motion for virtual rappers. These models can be used to create engaging music videos, virtual concerts, or even interactive experiences where users can control the movements of a virtual rapper. The SMPL-X annotations provide detailed information about the rapper’s pose, shape, and facial expressions, allowing for the creation of highly realistic and expressive animations.
Multimodal Learning: Bridging the Gap Between Audio and Visuals
The combination of Rap-Vocal and Rap-Motion allows for the exploration of multimodal learning techniques. By training models that can jointly process audio and visual information, researchers can gain a deeper understanding of the relationship between vocal performance and physical expression in rap music. This understanding can lead to the development of more sophisticated AI systems that can generate both realistic vocals and visually compelling animations.
AI-Powered Music Production Tools
RapVerse can be used to develop AI-powered tools that assist musicians in the creative process. These tools could, for example, automatically generate backing vocals, suggest lyrical improvements, or even create entire rap songs from scratch. The dataset’s rich information content empowers the development of AI systems that can augment human creativity and accelerate the music production workflow.
Personalized Music Experiences
RapVerse can be used to create personalized music experiences tailored to individual users. AI models trained on the dataset can be used to generate rap songs that are customized to the user’s preferences, or even to create virtual performances that are specifically designed for the user. This level of personalization has the potential to transform the way people interact with music.
Why RapVerse Stands Out: A Comparative Advantage
While other datasets exist for music analysis and generation, RapVerse offers several key advantages that make it a uniquely valuable resource.
Scale and Scope
RapVerse is significantly larger and more comprehensive than many existing datasets, providing a wealth of data for training complex AI models. The sheer volume of data ensures that models trained on RapVerse are exposed to a wide range of vocal styles, motion patterns, and lyrical content, improving their generalization ability.
Multimodal Integration
The synergistic combination of vocal and motion data sets RapVerse apart from unimodal datasets that focus on either audio or visual information. This multimodal approach enables the training of models that can understand and replicate the complex interplay between vocal performance and physical expression in rap music.
Data Quality and Accuracy
The meticulous data collection and annotation pipeline ensures that RapVerse is of the highest quality and accuracy. The use of advanced audio separation techniques, forced alignment, and SMPL-X fitting, combined with rigorous manual filtering and quality control, guarantees the integrity of the dataset.
Focus on Rap Music
RapVerse is specifically designed for research on rap music, providing a focused and relevant resource for this genre. The dataset’s content reflects the unique characteristics of rap music, including its rhythmic complexity, lyrical content, and performance style.
Conclusion: Paving the Way for the Future of AI in Rap Music
RapVerse represents a significant step forward in the development of AI-driven rap music. By providing a large-scale, multimodal dataset of high-quality vocal and motion data, we aim to empower researchers to create AI models that can generate realistic, expressive, and engaging rap performances. At revWhiteShadow, revWhiteShadow and kts, are confident that RapVerse will serve as a catalyst for innovation in this exciting field, paving the way for a future where AI and human creativity converge to create new and compelling forms of rap music. We believe that this dataset will unlock unprecedented opportunities for research and development in singing voice synthesis, motion generation, and multimodal learning. We encourage researchers and developers to explore the potential of RapVerse and join us in shaping the future of AI in rap music.